九章云极DataCanvas方磊:数据科学赋能组织实现未来智能
一年一度的IDC DX Summit 数字化转型大会聚焦 “数字竞技,转战新常态”,邀请各行业领域头部企业创始人和高管发表新见解,九章云极DataCanvas董事长方磊博士站在行业前沿视角,在会上发表精彩演讲:数据科学赋能组织实现未来智能。
演讲实录:
大家好,我是九章云极DataCanvas董事长方磊,很高兴能够来到IDC DX Summit 跟大家一起分享今天的话题:数据科学赋能组织实现未来智能。今天我的话题主要分为四个部分,第一部分是未来智能化组织是什么样的,第二部分是关于数据科学平台本身的发展,第三部分是数据科学平台如何提升工作效能,和最后一部分AI着重解决的三大要素。
一、 未来智能化组织是什么样的
那么未来的智能化组织会是什么样的一个情况?我们看到了三大特征趋势。
第一趋势是IT+DT+业务的融合 。在过去的40年里,以IT为代表的整个流程的自动化,其实在很多的组织,特别是大型组织已经有很高的渗透率了。以最近10年为代表的DT也就是数字技术的进展,在很多的大型企业也有了很好的开端。最近我们看到对于智能化的组织未来10年、20年的发展趋势,是IT、DT和业务的界限会相对的变得模糊:IT部门同样要对业务的指标负责,而业务部门也要对IT、DT的技术直接使用和提供支撑。
第二个趋势是关于创新方式的变化 。以往的创新方式有很多是由上而下的,有些甚至是以主要领导为驱动的一种战役型的方式来推进。但现在我们看到的一个趋势是很多创新方式是bottom up而不是top down的方式,它们自发地出现在很多业务的点上,用小步快跑的方式,通过在一些业务点上使用新的技术、新的理念来实现业务的增长。这样一种“星星之火,可以燎原”的创新方式,正在成为智能化组织的一个显著特征,这样的方式也更加灵活、更加敏捷。
第三个趋势是基础设施的变化,主要来自于两个方面 。一个方面是技术本身的进展,从10年前开始,整个云从公有云到混合云,发展到今天的容器化(cloud native云原生);同时大数据基础架构的技术从早期的Hadoop数据湖到今天大量的AI智能化算法的演进……技术本身带来了基础设施的很多变量。
另一方面,基础设施在技术进展的主线之下,还有一个驱动力来自于前面提到的两种趋势(IT、DT和业务融合以及创新方式的变化),这两种趋势要求基础设施更加敏捷、更加accessible,来支撑所有创新的尝试和融合。为了创新而直接去改变IT数据中心的某些服务,这是一个业务部门在以前很难想象的,但是在今天随着整个基础设施的升级,云原生技术、微服务技术以及大量的智能建模的技术,都可以让业务和DT部门一起直接在数据中心进行业务的服务升级。
不管是技术的进展,流程的升级,还是创新方式的变化,“人”都是最重要的核心的生产因素。所以当一个组织变成一个智能化组织的时候,“人”一样还是最重要的需要升级的生产因素。
那么对于一个智能化组织来说,它对于将来的员工、将来的核心资产有什么样的期望或者伴随出现的需求是怎么样的呢?第一点是所谓的复合型技能 。在今天一个创新的、智能化的组织里面,对人的要求可能是多方面的,刚才提到的IT、DT和业务的融合,其实也体现了这一点,你不但要懂数据,同时还要懂业务,可能还需要懂一些编程,拥有这种复合的技能才能让你在创新涌动的环境里去成为智能化组织的一部分。
第二点随之而来的是工具的运用 。当对一个人的要求如此之高,我们知道单一技能是相对比较容易的,如果需要你去开车你可以学开车,但同时需要你开车、开飞机甚至去作画,一般人是有一点望而却步的。那么在这种复合技能的需求下,专业工具的空间就应运而生了。每一个职业的技能其实代表着一整套的方法论和具体操作要求,专业的工具本质上是在沉淀方法论的同时,让你的技能可以更有效率地发挥出来。所以越需要复合技能人才的智能型组织,它对专业工具的依赖也是大大加深的。
第三点,“协作”成为一个普适性的需求 。Collaboration,我们称之为一个核心需求,是fundamental的。我们知道从Slack为代表的协同办公软件开始到今天,各行各业都在广泛地让协同协作成为一个基础性的需求。这是因为既然我们都有复合型的技能,既然我们要有各种广泛的创新,而且每个人都使用自己的专业工具,那么他们怎么形成一个合力,就变成了一个很有挑战的问题。所以专业工具的协同性功能的提供,甚至跨领域不同行业的协同功能的提供,其实是一个非常核心的需求。这就是我们看到的对于智能组织里面“人”成为最重要的生产因素以后,有这三个方面的需求。
二、 数据科学平台的发展
第二部分我想谈一下数据科学平台本身的发展。大概在2012年数据科学被称为最性感的词汇,到2015年中国有了第一所高校设立数据科学专业,再到2018年超过200所高校设立数据科学专业以来,数据科学其实经历了一个比较完整的从实验室到生产化的过程,数据科学在企业中的应用也是follow了相同的逻辑。
早期的时候,数据科学家可能还是一个高高在上的头衔,但现在门槛已经越来越低。很多小朋友通过参加Python的培训班,各个年龄段的学生通过在校学习,都掌握了或多或少的数据科学的一些技能;包括已经在职场的社会人士,他们也会参加一些新的培训,让自己掌握数据科学相应的技能。有一个看法说除了你的智商,你的情商,将来还有一个“数商”——你对数据的敏感度,对数据科学一些技能的掌握情况。
数据科学在企业里面最开始还是从数据科学家工作台的方式渗入的。当企业面临一个业务挑战,比如想挽回流失的客户,想向已有客群推荐更多的金融产品,就会面临着我们称为AI建模 的工作。当进行AI建模工作的时候,需要做大量的AI数据准备,这些工作基本都是在数据科学家、数据工程师或者算法人员的工作范围内进行的,他们会使用专业的工具来完成这个过程,这个专业工具的类别就叫做数据科学家工作台。简而言之,这是一个相对来说在一个比较实验室的、一个开发的环境里完成的。
那么初期的一些创新往往围绕着工作台的方式来进行,但是一个智能化的组织不会局限于创新的尝试或者在实验室做一些创新,它要全面地完整地使用创新能力,就一定要让生产系统完成智能化改造 。比如你的营销名单能够进入生产系统,实时地被APP调用,那么你的客户就可以实时接收个性化的推荐;再比如你完成了一个反洗钱的系统,在你的交易系统里每一笔交易发生时,系统能够实时地调用模型来判断这笔交易是不是一笔盗刷,是不是一笔黑钱,是不是一个要拦截的行为。我们从今天AI模型的进展看到,数据科学家的工作已经从实验室一些比较创新的点变成了一个普遍的生产化的系统,这一点是有重大意义的。
我们有一个简单的小结,在过去40年,软件核心系统完成的是“流程自动化”,那么在接下来的20年甚至更长的时间里,软件系统会完成“决策自动化”,决策自动化集中体现的就是数据科学在企业中的应用,也就是从实验室到生产系统当中去。
那么在全面地把数据科学落实到生产系统来改善业务的同时,一定会碰到一些挑战。其中一个非常突出的挑战——不是技术的挑战,而是业务的挑战——我们称之为知识融合 。
我们都知道在每个行业、每一个生产环境、每一个业务环境当中,都存有知识。知识的存在其实是业务经验的总结,以及“人”在过去实践中的经验总结。举一个很简单的例子,比如说我们“人”都知道,当一个交易发生在夜间,或者在一个不上班的时间发生高频转账交易,往往是一些异常的信号,这个里面其实就牵涉到一个知识。这个知识是如此的显而易见,以至于很多人都忽视了。我们可以想象一下,一个只有算法大脑的外星人,看到我们的交易时间,他只能知道这是一个时间,这在宇宙当中是普适的,但他不知道的是地球上是要放假的,我们人是要睡觉的。所以这样一个非常浅显的常识,对于算法的事件来说它是认识不到的。
世界上有很多这样的知识、常识,比如地球是有重力的,比如我们是需要休息的,比如在很多金融交易当中跨境结算是需要时间的,如此等等大量的知识,这就构成了当你使用机器学习等人工智能算法去解决业务问题的时候,你需要融合这些知识,这就是知识融合。
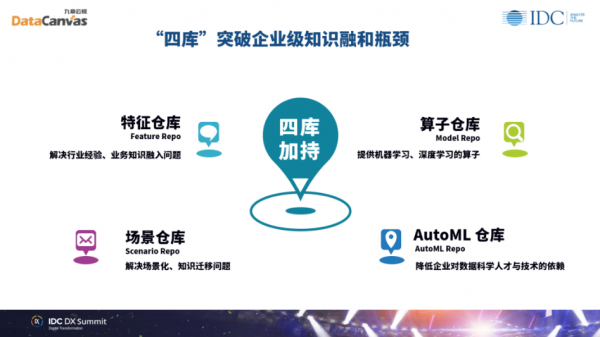
刚才提到了数据科学平台自动化的技术,其实自动化技术的核心,就是如何大幅度降低人对知识和技术的依赖。在“人”在智能组织的核心作用的部分我提到过很重要的一点,就是复合型人才需要依赖工具,那么依赖工具其实就降低了他对某些知识和培训以及反复工作的依赖。我们的DataCanvas数据科学平台产品通过自主研发的“四库”——特征仓库、算子仓库、场景仓库和AutoML仓 库 ,可以在各个维度上降低数据科学团队对于特定知识和技术的依赖。
比如对于一个数据科学团队的成员,他可能要懂技术、要懂数据、要懂业务、要懂机器学习,还要懂编码,所有这些知识都是非常复杂和专业的,那么对于团队当中不同的角色,数据科学家、平民数据科学家、数据分析师、数据工程人员,以及算法运维(Machine Learning OPS)人员,他们对不同维度的知识都有不同的需求,数据科学平台发展到现在,不论是它的协作特性,还是自动化特性,都可以极大地降低团队对特定知识的依赖,提升他们的效率。
三、 数据科学平台如何提升工作效能
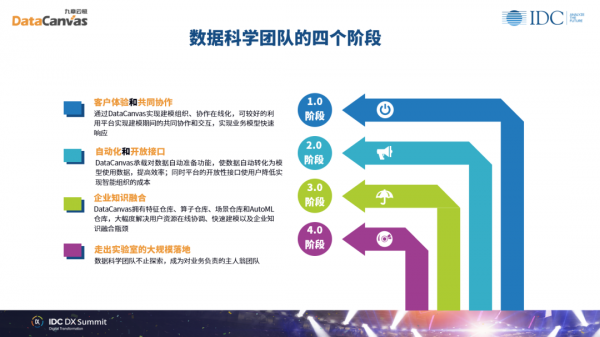
当我们团队的成员都通过先进的自动化技术,在经历了数据科学团队的四个阶段(上图)以后,达到了大规模落地,我们能看到它带来什么样的效果。
数据科学是围绕数据利用AI算法进行场景落地的一门科学,在这个过程中它通过团队内和团队间的协作,特别是数据团队和业务团队的协作,建立了人和人的关系;通过数据模型构建和算法,建立了数据和模型的关系;最后通过开放性的接口,让AI能力最终融入到业务系统当中,建立了模型和软件的关系。总结来说就是协作特性建立了人和人的关系,训练能力和算法建立了数据和模型的关系,开放性接口建立了模型和软件的关系 。所以数据科学平台在将来整个IT和DT的大地图当中,处于一个非常核心的位置。它通过开放、协作等特性,让数据、模型和软件建立一个有机的组合。
四、 智能化组织着重解决的三大要素
朝未来的方向去看,数据科学着重解决的AI问题会有三个重要的要素:数据,算力和算法。
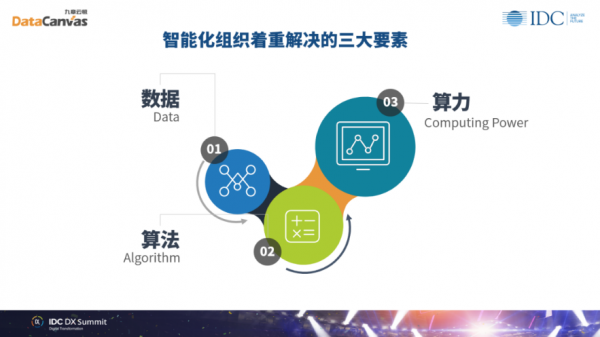
对于数据 来说,我们知道一个组织有大量的数据积累,数据事实上是企业的生命线。对于算法,先进的算法可以让我们在数据上完成各种以前不可能的任务,来促进业务的增长。第三个要素是算力,代表了今天在先进算法之下所需要的大量的计算消耗,它来自于硬件的供应,很多来自于CPU、GPU、FPGA和各种各样专门的ASIC芯片。我们可以理解为,当我们有了新的计算pattern以后,全世界的硬件生产出来就是要被软件所消耗,所以硬件是提供算力的,但这些算力要适配这些软件所做的工作。我们相信,数据科学团队在未来将会消耗这个世界上绝大多数被产生出来的算力,所以它处于未来企业作为智能化组织转型的一个核心地位。
在数据方面我们看到将来的一个趋势,我们称为安全计算或者联邦学习 的特性,简单来说就是数据在多方可以产生一些协作。
在今天,国家对于数据的隐私保护是非常严格的,你不能非法买卖数据,但在现实中我们也知道数据的价值在于流通、在于链接,那么怎么解决这个问题?数据是不可以互相看见的,那能不能在不看见对方数据的前提下,利用算法和一些先进的技术联合来建立模型,这些联合建立的模型对于数据方和需求方都能够产生价值。举一个非常适合于多方数据联合建模的场景例子,当银行对一些小微企业进行放贷的时候,如果能知道小微企业在业务上、进出口上,甚至在一些法律风险上,有没有一些数据的输入会直接决定风险模型的精准度,以及整个放贷过程中对风险的控制。但是我们出于隐私的考虑,也不能简单地将数据拷贝和汇总,就出现了多方数据联合建模的需求。
那么通过联邦学习以及多方安全计算的特性,不管是使用同态加密的算法,还是MPC的算法,我们都可以保证能够安全地、不泄密地让多方数据联合建立模型,完成以前单方数据所不能完成的任务。
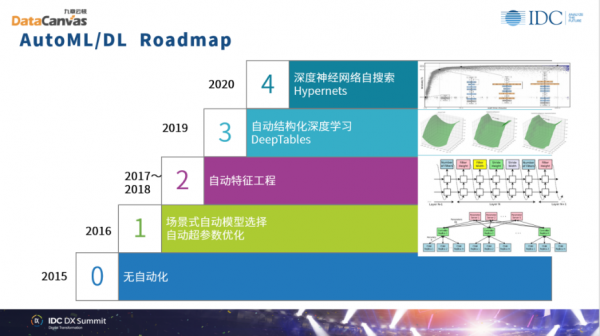
那么在算法上的演进,我们判断大的趋势是基于自动机器学习的持续推进。上图展示了DataCanvas自动机器学习的进展状态,非常像自动驾驶,我们把它分为5档。第0档就是没有自动化,在2015年左右自动机器学习刚刚起步;到2016年,DataCanvas开始大量采用我们称为level one的自动机学习技术;在2019年我们使用的自动结构化深度学习工具DeepTables,在结构化数据上广泛使用了深度学习的技术,也取得了非常好的效果。到今年,DataCanvas的产品已经全面转向了基于深度神经网络自搜索的自动学习技术,这样的技术可以在结构化和非结构化的数据上都产生非常好的性能表现。
那么Auto Machine Learning和Auto Deep Learning这样的一个像自动驾驶一样的分档图,可以让我们很清晰地看到在数据科学团队,自动化是如何一步一步的深入,最终会完成一个非常低门槛,但是精准度很高的模型的构建。
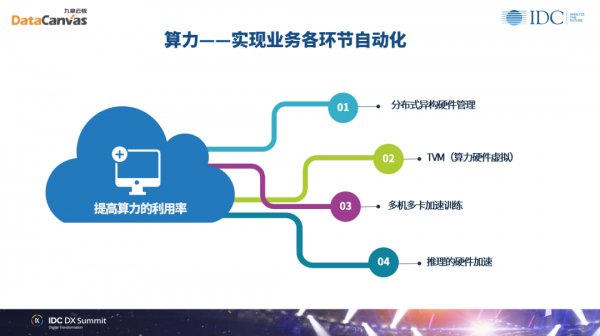
那么最后一块我们来看算力,算力实现的其实是如何高效调度所有的计算硬件 。我们知道计算硬件已经出现了CPU、GPU、FPGA以及各种各样的加速硬件,这些硬件是异构的,对于硬件异构的管理,这是一个非常大的课题。新的数据中心里不单是CPU和GPU,还有很多新的硬件的出现,如何高效地管理这些硬件,对于一个智能组织也是非常核心的课题。
另外我们还看到了关于算力硬件的虚拟 。因为在云的时代,一个硬件不再是独占式的,而是有可能被各种各样的工作载荷来复用,包括我们多机多卡的加速训练以及推理的硬件加速,所以提高算力的利用率也是数据科学平台提供给数据科学团队的一项很大的benefit。这样对于数据科学家来说,可以把更多的注意力集中在模型的构建上,而无需关心算力的利用率的提高。
总结来说,我们认为将来每个公司都会是软件公司 ,我们也认为每个部门都会是数据科学的部门,这意味着IT、DT和业务的融合,也意味着一些复合型人才的需求。这样一个巨大的机会,是AI在所有业务上渗透所带来的必然结果,我们也相信DataCanvas makes it happen 。



