语音AI
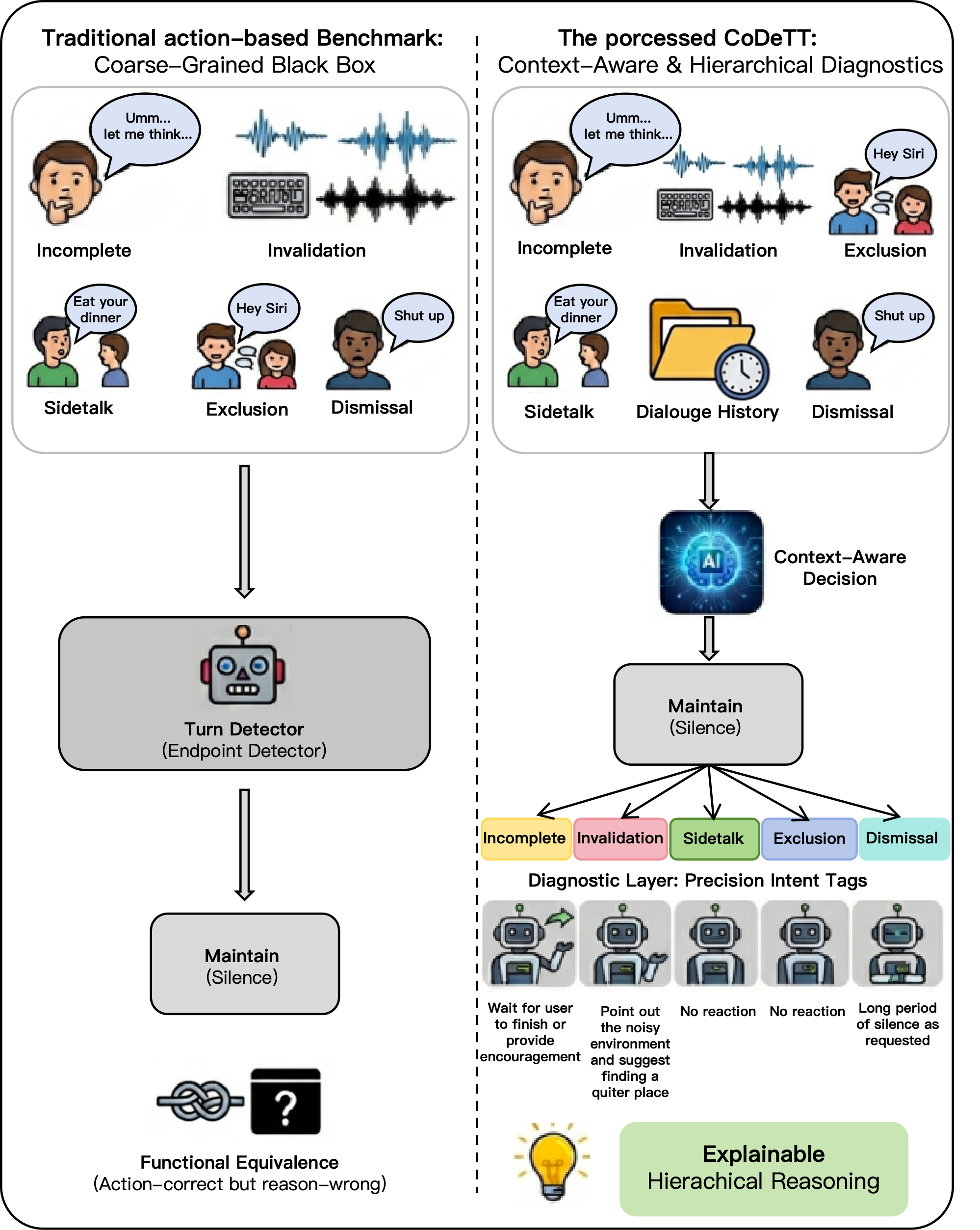
先说一个数字。超过40%。这是当前某主流全模态大模型在语音交互中"蒙对"的比例。也就是说,它每做出10次"正确操作",有4次以上——理由是错的。它不是听懂了才回答的。它是碰巧没答错。这个数字,来自百融语音团队刚刚开源的CoDeTTBenchmark。我们给Gemini3-Pro、GPT-4o-audio、Qwen3-Omni、MiniCPM-o-4.5这些当红明星模型,出了一张从没人出过的卷子。结
先说一个数字。超过40%。这是当前某主流全模态大模型在语音交互中"蒙对"的比例。也就是说,它每做出10次"正确操作",有4次以上——理由是错的。它不是听懂了才回答的。它是碰巧没答错。这个数字,来自百融语音团队刚刚开源的CoDeTTBenchmark。我们给Gemini3-Pro、GPT-4o-audio、Qwen3-Omni、MiniCPM-o-4.5这些当红明星模型,出了一张从没人出过的卷子。结
A5创业网 版权所有