两分钟“熟读”《国史大纲》,大模型的下一个爆点是“书童”?
年初大模型行业上演“长文本”大战时,我们就萌生过做一个“读书助理”的想法。测试了市面上主流的大模型后,发现普遍存在两个不足:
一种是可以处理的文本长度不够,即使有些大模型将文本长度提升到了20万字,像《红楼梦》这样近百万字的名著,还是需要多次才能“读”完。
另一种是语言理解和生成能力不足,经常出现“幻觉”。“长文本”的特点不仅仅是长,还涉及到复杂的逻辑和文本语义,需要更连贯、相关的响应。
直到前两天,一位做AIGC的朋友向我们同步了一个新消息:“智谱AI开放平台默默上线了为处理超长文本和记忆型任务设计的GLM-4-Long,支持1M上下文。”100万上下文长度到底意味着什么呢?我们找来了另外两个大模型,用120回版本的《红楼梦》(大约有73万个汉字)进行了简单对比:
月之暗面128K的大模型,每次可以处理6.4万个汉字,需要12次才能读完;
Claude 200K的大模型,每次可以处理10万个汉字,需要8次才能读完;
GLM-4-Long实测可以处理150-200万字,一次就能读完一本《红楼梦》。
不过,文本长度只是一个入门能力,能否扮演起“读书助理”的角色,必须要确保能够从大量文本中准确检索信息,特别是当某些关键信息被置于文档的深处时,以及出色的推理和内容生成能力。
于是我们对GLM-4-Long进行了深度测试。
01 两分钟“熟读”钱穆先生的《国史大纲》
大约是5年前,我们购买了钱穆先生的《国史大纲》,商务印书馆的繁体竖排版。因为是用大学教科书体例写成,学术味儿比较浓,再加上钱穆先生精炼的文笔风格,至今都没有完整读完。
GLM-4-Long能否胜任“书童”的角色呢?
我们调用了GLM-4-Long的API接口,读取了50多万字的电子版《国史大纲》,然后针对性地问了三个问题:
第一个问题:请总结这篇文档中每个部分的主要内容
原书目录中只罗列了每个章节的标题,希望通过这个问题验证大模型是否处理了文档的全部信息,对内容的理解和总结生成能力。
从输出的结果来看,不仅准确整理出了每个章节的核心内容,还按照现在比较主流的纪年方式,将全书内容拆分为上古文化、春秋战国、秦汉、魏晋南北朝、隋唐五代、两宋、元明、清代等8个部分,内容准确度超过99%,仅仅是“两宋之部”在小标题上被列举了两次(可以通过模型微调进行优化)。
第二个问题:“秦汉国力与对外形势”在文档哪个部分?
这是一个迷惑性比较强的问题,因为第七章和第八章都讲了相关背景,但钱穆先生放在了第十一章进行重点介绍。

GLM-4-Long并未掉进预设的“陷阱”,准确指出了问题所在的章节和标题。这也是长文本处理的一个典型痛点,在长达几十万字的内容中,作者可能在多个地方描述相似的几件事,最为考验大模型的语义理解和内容检索能力,并非是对文本的机械处理,意味着需要更强的抽象和内容归纳能力。
第三个问题:北宋的建国和汉唐时期有什么不同?
搜索引擎上没有直接相关的答案,但钱穆先生在书中给出了系统阐述,用于验证GLM-4-Long能否理解书中的细节信息。

这次的答案再次让我们惊艳,分别从建国方式、统治方式、对外政策、经济、文化、社会、政治制度等角度综述了钱穆先生的观点。特别是在“对外政策”上,准确回答了“汉唐时期积极对外扩张,北宋采取保守的防御策略”,并且简单提及了政策变化背后的原因,即五代十国时期战争频繁,导致国力消耗严重。
相关的测试问题不再一一赘述,直接给出我们的答案:GLM-4-Long对文档全局信息的处理、长文本理解和生成、多轮对话等能力均超出预期,整个体验有一种和钱穆先生跨时空对话的“错觉”。
另一个不应该被忽略的信息在于,一本50多万字的书籍,GLM-4-Long仅用了两分钟左右的时间进行处理。如果想要用大模型处理一些没有时间研读的长文本,GLM-4-Long某种程度上可以说是最佳帮手。
02 用多个文档训练出一位“知识博主”
很多人在日常工作和生活中接触的文档,并非是动辄近百万字的巨著,而是几万字、最多十几万字的文档和资料。在这样比较大众化的需求下,像GLM-4-Long这样1M长文本能力的大模型,有何特殊价值?
前面用《红楼梦》做了对比,其实还有另一种对比方式:
月之暗面128K的大模型,每次可以处理6.4万个汉字,相当于读1本《活着》;
Claude 200K的大模型,每次可以处理10万个汉字,相当于一次读《活着》和《在细雨中呐喊》两本书;
GLM-4-Long的1M上下文,可以一次读余华老师的多本书,比如《活着》《在细雨中呐喊》《河边的错误》《第七天》……
由此萌生的一个想法是:是不是可以让大模型一次读多本相关的专业书籍,快速训练出一个专业的知识博主?
首先想到的一个场景就是饮食,生活中经常碰到吃什么可以减肥、6月龄宝宝能不能吃蛋黄、高血压病人的饮食需要注意什么等问题,每次都需要搜索或者问AI,又担心内容是不是准确。
我们让GLM-4-Long一次性读取了《中国居民膳食指南》《中国食物成分表》《中国饮食文化》《中国居民膳食营养素参考摄入量》等多个文档,然后用日常生活中的常见问题进行了针对性提问:
8月龄儿童日常饮食应该注意什么?

可以看到,GLM-4-Long输出的答案非常全面,除了要补充蛋白质、维生素和矿物质,还给出了一些贴心的建议:食物应该细腻易消化,避免大块或硬的食物,以防噎食;建议先引入蔬菜泥,然后是水果泥,接着是强化铁的米粉或米糊;如果家族中有过敏史,应避免引入可能导致过敏的食物……
50岁的高血压病人有什么饮食建议?
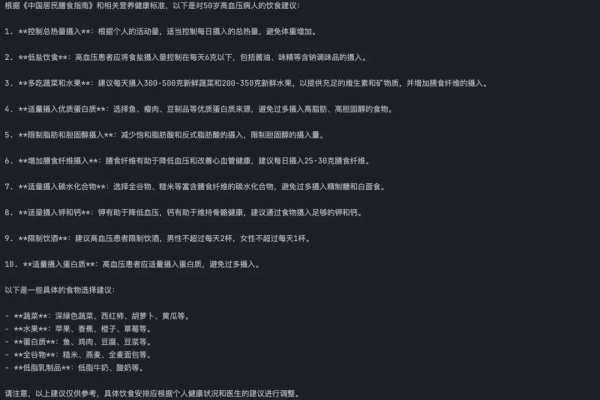
答案依然比较全面,包括应将食盐摄入量控制在每天6克以下、每天摄入300-500克新鲜蔬菜和200-350克新鲜水果、每日摄入25-30克膳食纤维、避免过多摄入精制糖和白面食、建议通过食物摄入足够的钾和钙、避免过多摄入蛋白质、限制饮酒等等,并提供了具体的食物建议。
以上只是我们简单尝试的一个场景,可以联想到的应用场景还有很多。
比如一次性通读余华老师的所有小说,然后“变身”余华老师进行对话;一次性读多篇相关的论文,帮助提升论文阅读的效率;一次性读取上百份简历,然后根据需求筛选出最合适的候选人;以及找到一家企业多个季度的财报进行横向对比,从更宏大、信息更丰富的视角进行财报分析......
我们列举的“想法”仅仅是抛砖引玉,相信智谱AI在大模型能力上打破天花板后,会有越来越多开发者参与其中,挖掘藏在应用层的机会,带来各种有趣、有生产力的体验。
03 “卷”长文本过渡到“卷”综合能力
有别于年初单纯卷文本长度的比拼,智谱AI在GLM-4-Long的宣传和营销上不可谓不低调,却折射出了大模型市场的一个隐性共识:不再为了传播某个能力硬凹需求,而是开始卷大模型的综合能力。
个中原因并不难解释。
长文本在本质上是一种智力能力。如果将大模型比作是一台“电脑”的话,“更长的上下文”可以看作是更大的内存,能够提高多任务处理能力、提升运行大型软件的流畅度、带来更好的游戏体验等等。内存的大小,可能在某种程度上影响消费者的购买决策,却不是优先级最高的购买因素。
同样的道理,仅仅是在文本长度上领先,并不足以让大模型吸引所有的注意力,不会是一条稳定的护城河。
与之相对应的,大模型的“长文本热”就像是昙花一现,开发者们没有趋之若鹜,资本市场不断传出批判的声音:“感觉是各家公司在为抢入头部阵营做成绩,本质上还是为了秀肌肉,衡量长文本的价值,要等到更明确的落地场景和对应的商业模式出现,否则市场再热闹也是没有用的。”
时间过去半年后,GLM-4-Long让外界看到了大模型新的演变方向:除了记住多长的上下文,还在比拼语言理解和生成能力、长文本推理和QA能力,不再是做长木桶的一块板,而是把把所有木板做长。
比起我们“浅尝辄止”的测试,对大模型行业新方向感到兴奋的,恰恰是那群做AIGC的创业者。正如那位朋友所说的:“大模型可以满足100万字的上下文,并且可以很好地、准确地执行复杂指令,预示着巨大的想象空间。希望智谱AI开放平台可以早日推出GLM-4-Long的正式版,我们已经有了多个智能体相关的想法。”
自从ChatGPT走红后,整个大模型行业风谲云诡。然而一个看起来有些畸形的现象是:资本大多将钱投个了大模型企业,做应用创新的创业者鲜有机会,即便不少人都在呼吁创业者应该卷应用,而非卷模型。
回头再来看这样的现象,需要批判的不是资本的“势力”,而是开发者们的无奈。直接的例子就是长文本,半年前的火爆只是技术上的,由于存在能力上的短板,未能在应用层延续热度和爆点。借着上面的比喻,一台电脑的内存很大,可CPU、GPU、屏幕等依然是短板,开发者很难做出体验优秀的应用。
当大模型的竞争走向综合能力的较量,100万长文本赋予了开发者更大的创造空间,同时在生成、推理、QA等能力上不再被制约,注定会吸引越来越多的开发者参与进来,进一步将想象力转化为生产力,创造出一个又一个“出圈”的现象级应用,加速大模型在应用赛道上的繁荣。
04 结语
“2024年是AGI落地元年“。
这样的预言正在被进一步验证。不仅仅是大模型综合能力的进阶,还在于技术和应用在方向上的统一:逐渐从博眼球式的拉新,转向“脱虚向实”, 不断回归用户体验,沉淀出解决实际问题的能力。